Оттачиваем мастерство работы с cURL. Функции обратного вызова
Итак, начнем. Для начала давайте определимся, что именно нам надо делать. При клике на ссылку, для подсчета количества кликов, нам надо специальным скриптом засчитать клик, а после предоставить посетителю интересующую его информацию (сделать редирект на нужный файл). В принципе, последовательность (за счет клика и выдача информации) можно поменять местами, однако учтите, что если счетчик используется для подсчета скачиваний файлов, то для того чтобы после скачки файла выполнялся скрипт, потребуется писать специальный скрипт-загрузчик файлов. Зачем вам лишние проблемы? Такой же принцип работы будет и у счетчика посещений. В данном случае, для ускорения загрузки страницы можно обойтись без редиректа, а просто вставить код счетчика в загружаемую страницу.
Вроде разобрались, так? Ну, а теперь давайте приступим к разборке не сложного кода для реализации всех наших идей. Для простоты примера, а также для того чтобы скрипт мог работать на любом хостинге, данные будем хранить в файле.
$f =fopen("stat.dat ","a+ "); flock($f ,LOCK_EX); $count =fread($f,100); @$count ++; ftruncate($f ,0); fwrite($f ,$count); fflush($f ); flock($f ,LOCK_UN); fclose($f ); |
Да, вы не ошиблись, это и есть весь скрипт. А теперь давайте разберемся, что и как в нем работает.
Первой строчкой кода - $f =fopen("stat.dat ","a+ "); мы открываем файл stat.dat для чтения и записи, связываем его с файловой переменной $f. Именно этот файл будет хранить данные о состоянии счетчика. Для правильной работы советую устанавливать для данного файла права доступа 777 или аналогичные с полным доступом на чтение и запись.
Следующая строчка - flock($f ,LOCK_EX); очень важна для работоспособности скрипта. Что она делает? Она на время работы данного скрипта (или до ее снятия) блокирует доступ к файлу для других скриптов или копии данного. Почему это так важно? Давайте представим ситуацию: в тот момент, когда пользователь1 кликает на ссылку, запускающую скрипт подсчета кликов, по той же ссылке кликает пользователь2, запуская копию того же скрипта. Как вы увидите далее, в зависимости от того, на какой стадии выполнения находится скрипт, запущенный пользователем1, скрипт запущенный пользователем2 и работающий параллельно со своей копией может попросту обнулить счетчик. Эту ошибку допускают практически все начинающие программисты на PHP, создавая подобные счетчики. Теперь, я думаю ясно, зачем нам блокировка доступа к файлу - в данном случае скрипт, запущенный пользователем2 будет ждать пока отработает скрипт, запущенный пользователем1 (не стоит пугаться, что это замедлит загрузку страниц - даже самые медленные серверы выполняют данный скрипт за сотые доли секунды).
С 3-й строчкой кода $count =fread($f ,100); все ясно. В переменную $count считываем значение счетчика.
Теперь нам осталось произвести запись в файл обновленных данных. Для этого нужно предварительно очистить файл ftruncate($f ,0); вот тут и может возникнуть та опасная ситуация с обнулением счетчика, про которую я говорил. Однако мы используем блокировку файла, так что бояться нечего.
Записываем обновленные данные о значении счетчика fwrite($f ,$count );
Для надежности принудительно очищаем буфер ввода/вывода для данного файла fflush($f );
Снимаем блокировку с файла flock($f ,LOCK_UN); на самом деле ее можно не снимать - она автоматически снимается после закрытия файла. Однако для полноты примера я ее все же написал.
Закрытие файла fclose($f ); тоже не обязательная функция т.к. все открытые скриптом файлы, после завершения его работы, автоматически закрываются. Но опять же, для полноты примера... =) кроме того, если на этом скрипт не заканчивается, а работать с файлом более не понадобится, рекомендуется сразу же закрывать файл.
Ну вот и все. Как видите совсем не сложно. Теперь для подсчета количества посещений, просто вставляйте данный код в страницу. А если же вы захотели подсчитать количество скачек какого-то файла, то вставляйте данный код в отдельный PHP файл, ссылку с имени файла заменяем на ссылку на данный скрипт, а в конец скрипта дописываем редирект на файл для скачки. Лучше всего его выполнить на PHP: Header("location:/download_dir/file_to_download.rar ");
Ах да. Надо же еще выводить значение счетчика, иначе считать то зачем =). Значения, разумеется, берем из файла. Можно сделать как в примере самого счетчика:
| $f
=fopen("stat.dat
","a+
"); flock($f ,LOCK_EX); $count =fread($f ,100); flock($f ,LOCK_UN); fclose($f ); Echo "Количество скачек/кликов: $count "; |
Запустите скаченный файл двойным кликом (нужно иметь виртуальную машину ).
3. Анонимность при проверке сайта на SQL-инъекции
Настройка Tor и Privoxy в Kali Linux
[Раздел в разработке]
Настройка Tor и Privoxy в Windows
[Раздел в разработке]
Настройки работы через прокси в jSQL Injection
[Раздел в разработке]
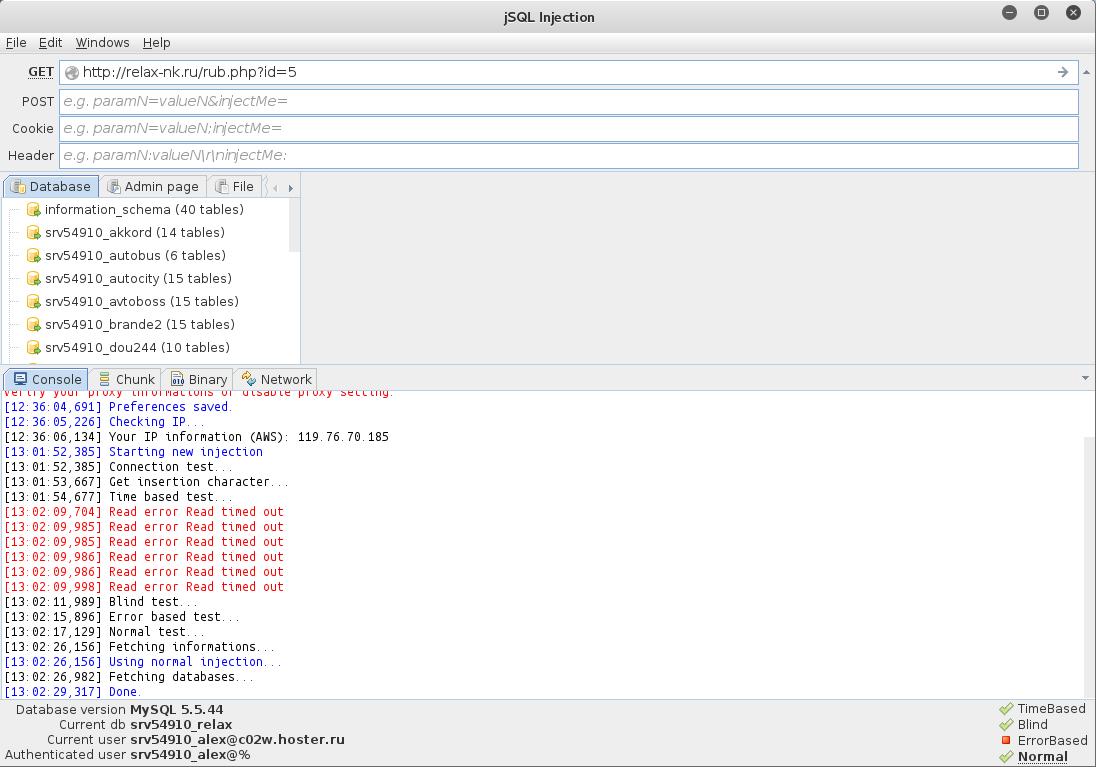
4. Проверка сайта на SQL-инъекции с jSQL Injection
Работа с программой крайне проста. Достаточно ввести адрес сайта и нажать ENTER.
На следующем скриншоте видно, что сайт уязвим сразу к трём видам SQL-инъекций (информация о них указана в правом нижнем углу). Кликая на названия инъекций можно переключить используемый метод:
Также нам уже выведены имеющиеся базы данных.
Можно посмотреть содержимое каждой таблицы:
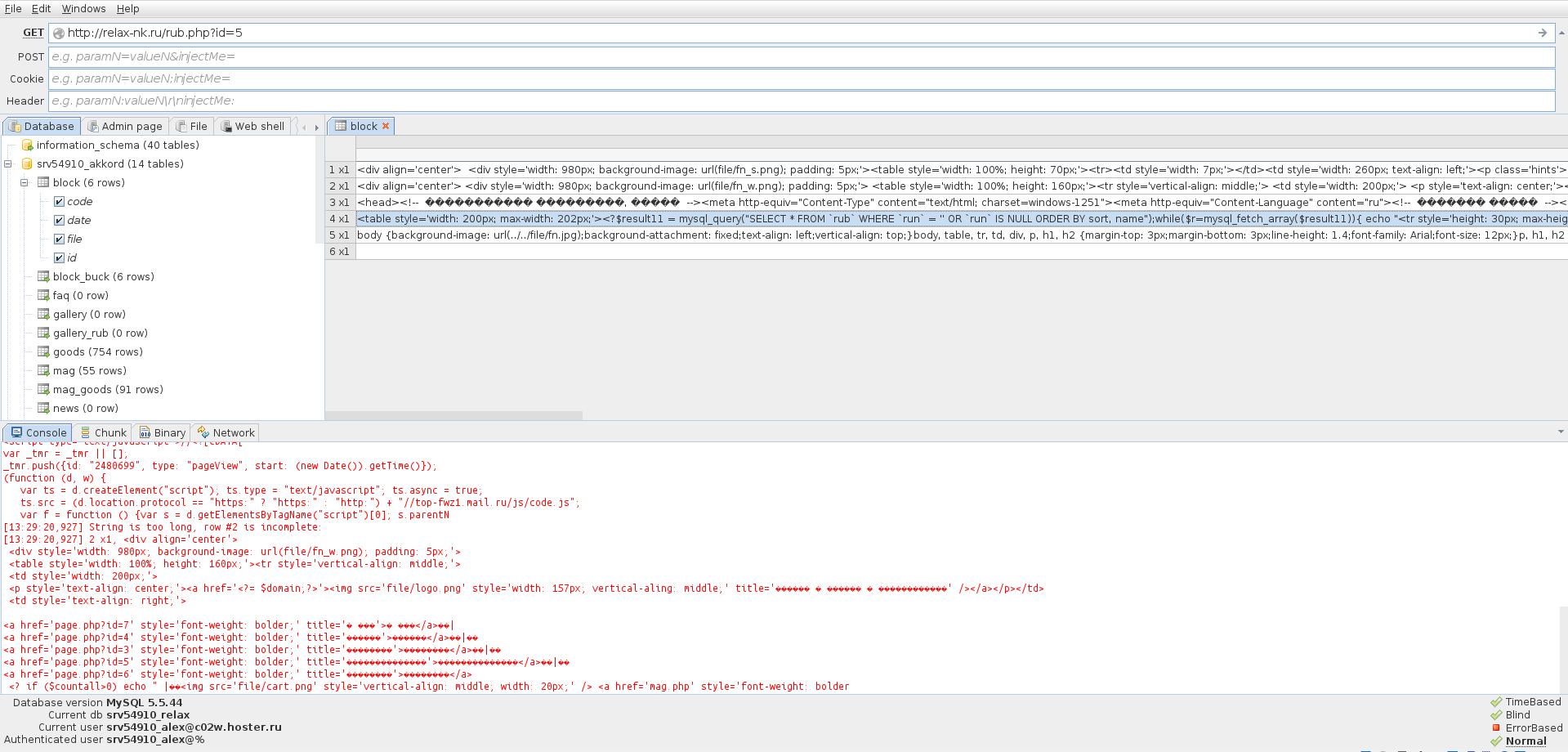
Обычно, самым интересным в таблицах являются учётные данные администратора.
Если вам повезло и вы нашли данные администратора — то радоваться рано. Нужно ещё найти админку, куда эти данные вводить.
5. Поиск админок с jSQL Injection
Для этого переходите на следующую вкладку. Здесь нас встречает список возможных адресов. Можете выбрать одну или несколько страниц для проверки:

Удобство заключается в том, что не нужно использовать другие программы.
К сожалению, нерадивых программистов, которые хранят пароли в открытом виде, не очень много. Довольно часто в строке пароля мы видим что-нибудь вроде
8743b52063cd84097a65d1633f5c74f5
Это хеш. Расшифровать его можно брутфорсом. И… jSQL Injection имеет встроенный брутфорсер.
6. Брутфорсинг хешей с помощью jSQL Injection
Несомненным удобство является то, что не нужно искать другие программы. Здесь имеется поддержка множества самых популярных хешей.
Это не самый оптимальный вариант. Для того, чтобы стать гуру в расшифровке хешей, рекомендуется Книга « » на русском языке.
Но, конечно, когда под рукой нет другой программы или нет времени на изучение, jSQL Injection со встроенной функцией брут-форса придётся очень кстати.

Присутствуют настройки: можно задать какие символы входят в пароль, диапазон длины пароля.
7. Операции с файлами после обнаружения SQL-инъекций
Кроме операций с базами данных — их чтение и модификация, в случае обнаружения SQL-инъекций возможно выполнение следующих файловых операций:
- чтение файлов на сервере
- выгрузка новых файлов на сервер
- выгрузка шеллов на сервер
И всё это реализовано в jSQL Injection!
Есть ограничения — у SQL-сервера должны быть файловые привилегии. У разумных системных администраторов они отключены и доступа к файловой системе получить не удастся.
Наличие файловых привилегий достаточно просто проверить. Перейдите в одну из вкладок (чтение файлов, создание шелла, закачка нового файла) и попытайтесь выполнить одну из указанных операций.
Ещё очень важное замечание — нам нужно знать точный абсолютный путь до файла с которым мы будем работать — иначе ничего не получится.
Посмотрите на следующий скриншот:
 На любую попытку операции с файлом нам отвечают: No FILE privilege
(нет файловых привелегий). И ничего здесь поделать нельзя.
На любую попытку операции с файлом нам отвечают: No FILE privilege
(нет файловых привелегий). И ничего здесь поделать нельзя.
Если вместо этого у вас другая ошибка:
Problem writing into [название_каталога]
Это означает, что вы неправильно указали абсолютный путь, в который нужно записывать файл.
Для того, чтобы предположить абсолютный путь, нужно, как минимум, знать операционную систему на которой работает сервер. Для этого переключитесь к вкладке Network.
Такая запись (строка Win64 ) даёт основание нам предположить, что мы имеем дело с ОС Windows:
Keep-Alive: timeout=5, max=99 Server: Apache/2.4.17 (Win64) PHP/7.0.0RC6 Connection: Keep-Alive Method: HTTP/1.1 200 OK Content-Length: 353 Date: Fri, 11 Dec 2015 11:48:31 GMT X-Powered-By: PHP/7.0.0RC6 Content-Type: text/html; charset=UTF-8
Здесь у нас какой-то из Unix (*BSD, Linux):
Transfer-Encoding: chunked Date: Fri, 11 Dec 2015 11:57:02 GMT Method: HTTP/1.1 200 OK Keep-Alive: timeout=3, max=100 Connection: keep-alive Content-Type: text/html X-Powered-By: PHP/5.3.29 Server: Apache/2.2.31 (Unix)
А здесь у нас CentOS:
Method: HTTP/1.1 200 OK Expires: Thu, 19 Nov 1981 08:52:00 GMT Set-Cookie: PHPSESSID=9p60gtunrv7g41iurr814h9rd0; path=/ Connection: keep-alive X-Cache-Lookup: MISS from t1.hoster.ru:6666 Server: Apache/2.2.15 (CentOS) X-Powered-By: PHP/5.4.37 X-Cache: MISS from t1.hoster.ru Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Pragma: no-cache Date: Fri, 11 Dec 2015 12:08:54 GMT Transfer-Encoding: chunked Content-Type: text/html; charset=WINDOWS-1251
В Windows типичной папкой для сайтов является C:\Server\data\htdocs\ . Но, на самом деле, если кто-то «додумался» делать сервер на Windows, то, весьма вероятно, этот человек ничего не слышал о привилегиях. Поэтому начинать попытки стоит прямо с каталога C:/Windows/:
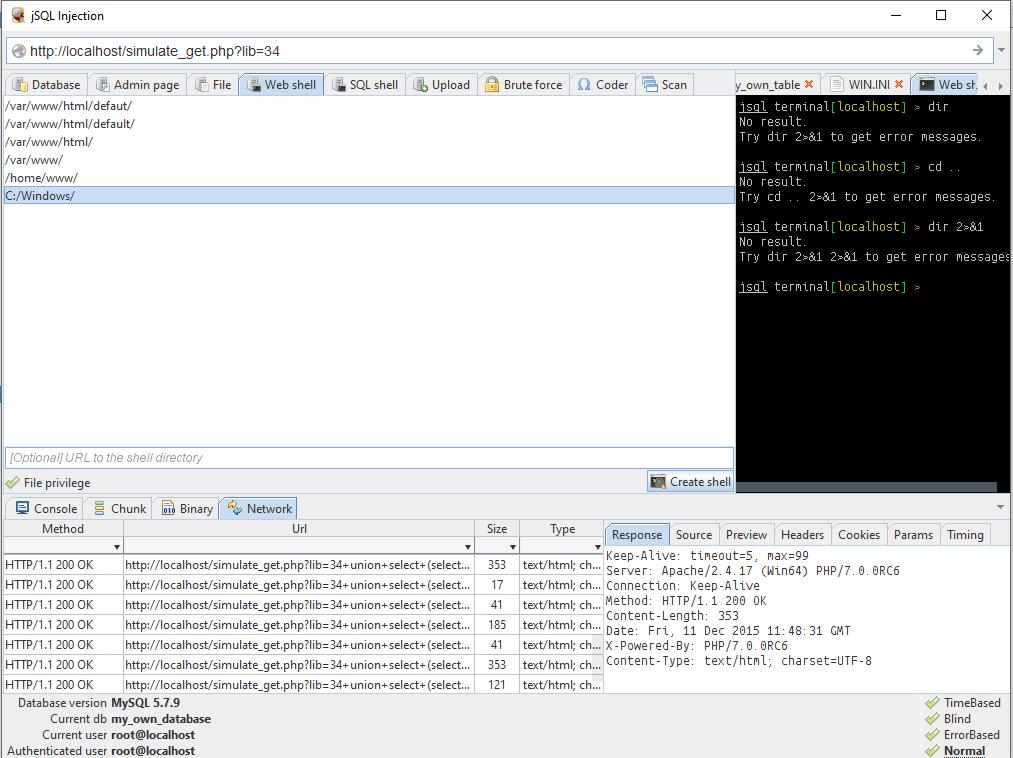
Как видим, всё прошло прекрасно с первого раза.
Но вот сами шеллы jSQL Injection у меня вызывают сомнения. Если есть файловые привилегии, то вы вполне можете закачать что-нибудь с веб-интерфейсом.
8. Массовая проверка сайтов на SQL-инъекции
И даже эта функция есть у jSQL Injection. Всё предельно просто — загружаете список сайтов (можно импортировать из файла), выбираете те, которые хотите проверить и нажимаете соответствующую кнопку для начала операции.

Вывод по jSQL Injection
jSQL Injection хороший, мощный инструмент для поиска и последующего использования найденных на сайтах SQL-инъекций. Его несомненные плюсы: простота использования, встроенные сопутствующие функции. jSQL Injection может стать лучшим другом новичка при анализе веб-сайтов.
Из недостатков я бы отметил невозможность редактирования баз данных (по крайней мере я этого функционала не нашёл). Как и у всех инструментов с графическим интерфейсом, к недостаткам этой программы можно приписать невозможность использования в скриптах. Тем не менее некоторая автоматизация возможна и в этой программе — благодаря встроенной функции массовой проверки сайтов.
Программой jSQL Injection пользоваться значительно удобнее чем sqlmap . Но sqlmap поддерживает больше видов SQL-инъекций, имеет опции для работы с файловыми файерволами и некоторые другие функции.
Итог: jSQL Injection — лучший друг начинающего хакера.
Справку по данной программе в Энциклопедии Kali Linux вы найдёте на этой странице: http://kali.tools/?p=706
cURL - это специальный инструмент, который предназначен для того, чтобы передавать файлы и данные синтаксисом URL. Данная технология поддерживает множество протоколов, таких как HTTP, FTP, TELNET и многие другие. Изначально cURL было разработано для того, чтобы быть инструментом командной строки. К счастью для нас, библиотека cURL поддерживается языком программирования PHP. В этой статье мы рассмотрим некоторые расширенные функций cURL, а также затронем практическое применение полученных знаний средствами PHP.
Почему cURL?
На самом деле, существует немало альтернативных способов выборки содержания веб-страницы. Во многих случаях, главным образом из-за лени, я использовал простые PHP функции вместо cURL:
$content = file_get_contents("http://www.nettuts.com"); // или $lines = file("http://www.nettuts.com"); // или readfile("http://www.nettuts.com");
Однако данные функции не имеют фактически никакой гибкости и содержат огромное количество недостатков в том, что касается обработки ошибок и т.д. Кроме того, существуют определенные задачи, которые вы просто не можете решить благодаря этим стандартным функциям: взаимодействие с cookie, аутентификация, отправка формы, загрузка файлов и т.д.
cURL - это мощная библиотека, которая поддерживает множество различных протоколов, опций и обеспечивает подробную информацию о URL запросах.
Базовая структура
- Инициализация
- Назначение параметров
- Выполнение и выборка результата
- Освобождение памяти
// 1. инициализация $ch = curl_init(); // 2. указываем параметры, включая url curl_setopt($ch, CURLOPT_URL, "http://www.nettuts.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_HEADER, 0); // 3. получаем HTML в качестве результата $output = curl_exec($ch); // 4. закрываем соединение curl_close($ch);
Шаг #2 (то есть, вызов curl_setopt()) будем обсуждать в этой статье намного больше, чем все другие этапы, т.к. на этой стадии происходит всё самое интересное и полезное, что вам необходимо знать. В cURL существует огромное количество различных опций, которые должны быть указаны, для того чтобы иметь возможность сконфигурировать URL-запрос самым тщательным образом. Мы не будем рассматривать весь список целиком, а остановимся только на том, что я посчитаю нужным и полезным для этого урока. Всё остальное вы сможете изучить сами, если эта тема вас заинтересует.
Проверка Ошибки
Вдобавок, вы также можете использовать условные операторы для проверки выполнения операции на успех:
// ... $output = curl_exec($ch); if ($output === FALSE) { echo "cURL Error: " . curl_error($ch); } // ...
Тут прошу отметить для себя очень важный момент: мы должны использовать “=== false” для сравнения, вместо “== false”. Для тех, кто не в курсе, это поможет нам отличать пустой результат от булевого значения false, которое и будет указывать на ошибку.
Получение информации
Ещё одним дополнительным шагом является получение данных о cURL запросе, после того, как он был выполнен.
// ... curl_exec($ch); $info = curl_getinfo($ch); echo "Took " . $info["total_time"] . " seconds for url " . $info["url"]; // …
Возвращаемый массив содержит следующую информацию:
- “url”
- “content_type”
- “http_code”
- “header_size”
- “request_size”
- “filetime”
- “ssl_verify_result”
- “redirect_count”
- “total_time”
- “namelookup_time”
- “connect_time”
- “pretransfer_time”
- “size_upload”
- “size_download”
- “speed_download”
- “speed_upload”
- “download_content_length”
- “upload_content_length”
- “starttransfer_time”
- “redirect_time”
Обнаружение перенаправления в зависимости от браузера
В этом первом примере мы напишем код, который сможет обнаружить перенаправления URL, основанные на различных настройках браузера. Например, некоторые веб-сайты перенаправляют браузеры сотового телефона, или любого другого устройства.
Мы собираемся использовать опцию CURLOPT_HTTPHEADER для того, чтобы определить наши исходящие HTTP заголовки, включая название браузера пользователя и доступные языки. В конечном итоге мы сможем определить, какие сайты перенаправляют нас к разным URL.
// тестируем URL $urls = array("http://www.cnn.com", "http://www.mozilla.com", "http://www.facebook.com"); // тестируем браузеры $browsers = array("standard" => array ("user_agent" => "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 (.NET CLR 3.5.30729)", "language" => "en-us,en;q=0.5"), "iphone" => array ("user_agent" => "Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en) AppleWebKit/420+ (KHTML, like Gecko) Version/3.0 Mobile/1A537a Safari/419.3", "language" => "en"), "french" => array ("user_agent" => "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; GTB6; .NET CLR 2.0.50727)", "language" => "fr,fr-FR;q=0.5")); foreach ($urls as $url) { echo "URL: $url\n"; foreach ($browsers as $test_name => $browser) { $ch = curl_init(); // указываем url curl_setopt($ch, CURLOPT_URL, $url); // указываем заголовки для браузера curl_setopt($ch, CURLOPT_HTTPHEADER, array("User-Agent: {$browser["user_agent"]}", "Accept-Language: {$browser["language"]}")); // нам не нужно содержание страницы curl_setopt($ch, CURLOPT_NOBODY, 1); // нам необходимо получить HTTP заголовки curl_setopt($ch, CURLOPT_HEADER, 1); // возвращаем результаты вместо вывода curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $output = curl_exec($ch); curl_close($ch); // был ли HTTP редирект? if (preg_match("!Location: (.*)!", $output, $matches)) { echo "$test_name: redirects to $matches\n"; } else { echo "$test_name: no redirection\n"; } } echo "\n\n"; }
Сначала мы указываем список URL сайтов, которые будем проверять. Точнее, нам понадобятся адреса данных сайтов. Далее нам необходимо определить настройки браузера, чтобы протестировать каждый из этих URL. После этого мы воспользуемся циклом, в котором пробежимся по всем полученным результатам.
Приём, который мы используем в этом примере для того, чтобы задать настройки cURL, позволит нам получить не содержание страницы, а только HTTP-заголовки (сохраненные в $output). Далее, воспользовавшись простым regex, мы можем определить, присутствовала ли строка “Location:” в полученных заголовках.
Когда вы запустите данный код, то должны будете получить примерно следующий результат:
Создание POST запроса на определённый URL
При формировании GET запроса передаваемые данные могут быть переданы на URL через “строку запроса”. Например, когда Вы делаете поиск в Google, критерий поиска располагаются в адресной строке нового URL:
Http://www.google.com/search?q=ruseller
Для того чтобы сымитировать данный запрос, вам не нужно пользоваться средствами cURL. Если лень вас одолевает окончательно, воспользуйтесь функцией “file_get_contents()”, для того чтобы получить результат.
Но дело в том, что некоторые HTML-формы отправляют POST запросы. Данные этих форм транспортируются через тело HTTP запроса, а не как в предыдущем случае. Например, если вы заполнили форму на форуме и нажали на кнопку поиска, то скорее всего будет совершён POST запрос:
Http://codeigniter.com/forums/do_search/
Мы можем написать PHP скрипт, который может сымитировать этот вид URL запроса. Сначала давайте создадим простой файл для принятия и отображения POST данных. Назовём его post_output.php:
Print_r($_POST);
Затем мы создаем PHP скрипт, чтобы выполнить cURL запрос:
$url = "http://localhost/post_output.php"; $post_data = array ("foo" => "bar", "query" => "Nettuts", "action" => "Submit"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // указываем, что у нас POST запрос curl_setopt($ch, CURLOPT_POST, 1); // добавляем переменные curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $output = curl_exec($ch); curl_close($ch); echo $output;
При запуске данного скрипта вы должны получить подобный результат:

Таким образом, POST запрос был отправлен скрипту post_output.php, который в свою очередь, вывел суперглобальный массив $_POST, содержание которого мы получили при помощи cURL.
Загрузка файла
Сначала давайте создадим файл для того, чтобы сформировать его и отправить файлу upload_output.php:
Print_r($_FILES);
А вот и код скрипта, который выполняет указанный выше функционал:
$url = "http://localhost/upload_output.php"; $post_data = array ("foo" => "bar", // файл, который необходимо загрузить "upload" => "@C:/wamp/www/test.zip"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $output = curl_exec($ch); curl_close($ch); echo $output;
Когда вы хотите загрузить файл, все, что вам нужно сделать, так это передать его как обычную post переменную, предварительно поместив перед ней символ @. При запуске написанного скрипта вы получите следующий результат:

Множественный cURL
Одной из самых сильных сторон cURL является возможность создания "множественных" cURL обработчиков. Это позволяет вам открывать соединение к множеству URL одновременно и асинхронно.
В классическом варианте cURL запроса выполнение скрипта приостанавливается, и происходит ожидание завершения операции URL запроса, после чего работа скрипта может продолжиться. Если вы намереваетесь взаимодействовать с целым множеством URL, это приведёт к довольно-таки значительным затратам времени, поскольку в классическом варианте вы можете работать только с одним URL за один раз. Однако, мы можем исправить данную ситуацию, воспользовавшись специальными обработчиками.
Давайте рассмотрим пример кода, который я взял с php.net:
// создаём несколько cURL ресурсов $ch1 = curl_init(); $ch2 = curl_init(); // указываем URL и другие параметры curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/"); curl_setopt($ch1, CURLOPT_HEADER, 0); curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/"); curl_setopt($ch2, CURLOPT_HEADER, 0); //создаём множественный cURL обработчик $mh = curl_multi_init(); //добавляем несколько обработчиков curl_multi_add_handle($mh,$ch1); curl_multi_add_handle($mh,$ch2); $active = null; //выполнение do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); while ($active && $mrc == CURLM_OK) { if (curl_multi_select($mh) != -1) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); } } //закрытие curl_multi_remove_handle($mh, $ch1); curl_multi_remove_handle($mh, $ch2); curl_multi_close($mh);
Идея состоит в том, что вы можете использовать множественные cURL обработчики. Используя простой цикл, вы можете отследить, какие запросы ещё не выполнились.
В этом примере есть два основных цикла. Первый цикл do-while вызывает функцию curl_multi_exec(). Эта функция не блокируемая. Она выполняется с той скоростью, с которой может, и возвращает состояние запроса. Пока возвращенное значение является константой ‘CURLM_CALL_MULTI_PERFORM’, это означает, что работа ещё не завершена (например, в данный момент происходит отправка http заголовков в URL); Именно поэтому мы продолжаем проверять это возвращаемое значение, пока не получим другой результат.
В следующем цикле мы проверяем условие, пока переменная $active = "true". Она является вторым параметром для функции curl_multi_exec(). Значение данной переменной будет равно "true", до тех пор, пока какое-то из существующих изменений является активным. Далее мы вызываем функцию curl_multi_select(). Её выполнение "блокируется", пока существует хоть одно активное соединение, до тех пор, пока не будет получен ответ. Когда это произойдёт, мы возвращаемся в основной цикл, чтобы продолжить выполнение запросов.
А теперь давайте применим полученные знания на примере, который будет реально полезным для большого количества людей.
Проверяем ссылки в WordPress
Представьте себе блог с огромным количеством постов и сообщений, в каждом из которых есть ссылки на внешние интернет ресурсы. Некоторые из этих ссылок по различным причинам могли бы уже быть «мертвыми». Возможно, страница была удалена или сайт вовсе не работает.
Мы собираемся создать скрипт, который проанализирует все ссылки и найдёт незагружающиеся веб-сайты и страницы 404, после чего предоставит нам подробнейший отчёт.
Сразу же скажу, что это не пример создания плагина для WordPress. Это всего на всего хороший полигон для наших испытаний.
Давайте же наконец начнём. Сначала мы должны сделать выборку всех ссылок из базы данных:
// конфигурация $db_host = "localhost"; $db_user = "root"; $db_pass = ""; $db_name = "wordpress"; $excluded_domains = array("localhost", "www.mydomain.com"); $max_connections = 10; // инициализация переменных $url_list = array(); $working_urls = array(); $dead_urls = array(); $not_found_urls = array(); $active = null; // подключаемся к MySQL if (!mysql_connect($db_host, $db_user, $db_pass)) { die("Could not connect: " . mysql_error()); } if (!mysql_select_db($db_name)) { die("Could not select db: " . mysql_error()); } // выбираем все опубликованные посты, где есть ссылки $q = "SELECT post_content FROM wp_posts WHERE post_content LIKE "%href=%" AND post_status = "publish" AND post_type = "post""; $r = mysql_query($q) or die(mysql_error()); while ($d = mysql_fetch_assoc($r)) { // делаем выборку ссылок при помощи регулярных выражений if (preg_match_all("!href=\"(.*?)\"!", $d["post_content"], $matches)) { foreach ($matches as $url) { $tmp = parse_url($url); if (in_array($tmp["host"], $excluded_domains)) { continue; } $url_list = $url; } } } // убираем дубликаты $url_list = array_values(array_unique($url_list)); if (!$url_list) { die("No URL to check"); }
Сначала мы формируем конфигурационные данные для взаимодействия с базой данных, далее пишем список доменов, которые не будут участвовать в проверке ($excluded_domains). Также мы определяем число, характеризующее количество максимальных одновременных соединений, которые мы будем использовать в нашем скрипте ($max_connections). Затем мы присоединяемся к базе данных, выбираем посты, которые содержат ссылки, и накапливаем их в массив ($url_list).
Следующий код немного сложен, так что разберитесь в нём от начала до конца:
// 1. множественный обработчик $mh = curl_multi_init(); // 2. добавляем множество URL for ($i = 0; $i < $max_connections; $i++) { add_url_to_multi_handle($mh, $url_list); } // 3. инициализация выполнения do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 4. основной цикл while ($active && $mrc == CURLM_OK) { // 5. если всё прошло успешно if (curl_multi_select($mh) != -1) { // 6. делаем дело do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 7. если есть инфа? if ($mhinfo = curl_multi_info_read($mh)) { // это значит, что запрос завершился // 8. извлекаем инфу $chinfo = curl_getinfo($mhinfo["handle"]); // 9. мёртвая ссылка? if (!$chinfo["http_code"]) { $dead_urls = $chinfo["url"]; // 10. 404? } else if ($chinfo["http_code"] == 404) { $not_found_urls = $chinfo["url"]; // 11. рабочая } else { $working_urls = $chinfo["url"]; } // 12. чистим за собой curl_multi_remove_handle($mh, $mhinfo["handle"]); // в случае зацикливания, закомментируйте данный вызов curl_close($mhinfo["handle"]); // 13. добавляем новый url и продолжаем работу if (add_url_to_multi_handle($mh, $url_list)) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); } } } } // 14. завершение curl_multi_close($mh); echo "==Dead URLs==\n"; echo implode("\n",$dead_urls) . "\n\n"; echo "==404 URLs==\n"; echo implode("\n",$not_found_urls) . "\n\n"; echo "==Working URLs==\n"; echo implode("\n",$working_urls); function add_url_to_multi_handle($mh, $url_list) { static $index = 0; // если у нас есть ещё url, которые нужно достать if ($url_list[$index]) { // новый curl обработчик $ch = curl_init(); // указываем url curl_setopt($ch, CURLOPT_URL, $url_list[$index]); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); curl_setopt($ch, CURLOPT_NOBODY, 1); curl_multi_add_handle($mh, $ch); // переходим на следующий url $index++; return true; } else { // добавление новых URL завершено return false; } }
Тут я попытаюсь изложить всё по полочкам. Числа в списке соответствуют числам в комментарии.
- 1. Создаём множественный обработчик;
- 2. Функцию add_url_to_multi_handle() мы напишем чуть позже. Каждый раз, когда она будет вызываться, начнётся обработка нового url. Первоначально, мы добавляем 10 ($max_connections) URL;
- 3. Для того чтобы начать работу, мы должны запустить функцию curl_multi_exec(). До тех пор, пока она будет возвращать CURLM_CALL_MULTI_PERFORM, нам ещё есть, что делать. Это нам нужно, главным образом, для того, чтобы создать соединения;
- 4. Далее следует основной цикл, который будет выполняться до тех пор, пока у нас есть хоть одно активное соединение;
- 5. curl_multi_select() зависает в ожидании, пока поиск URL не завершится;
- 6. И снова мы должны заставить cURL выполнить некоторую работу, а именно, сделать выборку данных возвращаемого ответа;
- 7. Тут происходит проверка информации. В результате выполнения запроса будет возвращён массив;
- 8. В возвращенном массиве присутствует cURL обработчик. Его мы и будем использовать для того, чтобы выбрать информацию об отдельном cURL запросе;
- 9. Если ссылка была мертва, или время выполнения скрипта вышло, то нам не следует искать никакого http кода;
- 10. Если ссылка возвратила нам страницу 404, то http код будет содержать значение 404;
- 11. В противном случае, перед нами находится рабочая ссылка. (Вы можете добавить дополнительные проверки на код ошибки 500 и т.д...);
- 12. Далее мы удаляем cURL обработчик, потому что больше в нём не нуждаемся;
- 13. Теперь мы можем добавить другой url и запустить всё то, о чём говорили до этого;
- 14. На этом шаге скрипт завершает свою работу. Мы можем удалить всё, что нам не нужно и сформировать отчет;
- 15. В конце концов, напишем функцию, которая будет добавлять url в обработчик. Статическая переменная $index будет увеличиваться каждый раз, когда данная функция будет вызвана.
Я использовал данный скрипт на своем блоге (с некоторыми неработающими ссылками, которые добавил нарочно для того, чтобы протестировать его работу) и получил следующий результат:

В моём случае, скрипту потребовалось чуть меньше чем 2 секунды, чтобы пробежаться по 40 URL. Увеличение производительности является существенным при работе с еще большим количеством URL адресов. Если вы открываете десять соединений одновременно, то скрипт может выполниться в десять раз быстрее.
Пару слов о других полезных опциях cURL
HTTP Аутентификация
Если на URL адресе есть HTTP аутентификация, то вы без труда можете воспользоваться следующим скриптом:
$url = "http://www.somesite.com/members/"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // указываем имя и пароль curl_setopt($ch, CURLOPT_USERPWD, "myusername:mypassword"); // если перенаправление разрешено curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // то сохраним наши данные в cURL curl_setopt($ch, CURLOPT_UNRESTRICTED_AUTH, 1); $output = curl_exec($ch); curl_close($ch);
FTP загрузка
В PHP также существует библиотека для работы с FTP, но вам ничего не мешает и тут воспользоваться средствами cURL:
// открываем файл $file = fopen("/path/to/file", "r"); // в url должно быть следующее содержание $url = "ftp://username:[email protected]:21/path/to/new/file"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_UPLOAD, 1); curl_setopt($ch, CURLOPT_INFILE, $fp); curl_setopt($ch, CURLOPT_INFILESIZE, filesize("/path/to/file")); // указывам ASCII мод curl_setopt($ch, CURLOPT_FTPASCII, 1); $output = curl_exec($ch); curl_close($ch);
Используем Прокси
Вы можете выполнить свой URL запрос через прокси:
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL,"http://www.example.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // указываем адрес curl_setopt($ch, CURLOPT_PROXY, "11.11.11.11:8080"); // если необходимо предоставить имя пользователя и пароль curl_setopt($ch, CURLOPT_PROXYUSERPWD,"user:pass"); $output = curl_exec($ch); curl_close ($ch);
Функции обратного вызова
Также существует возможность указать функцию, которая будет срабатывать ещё до завершения работы cURL запроса. Например, пока содержание ответа загружается, вы можете начать использовать данные, не дожидаясь полной загрузки.
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL,"http://net.tutsplus.com"); curl_setopt($ch, CURLOPT_WRITEFUNCTION,"progress_function"); curl_exec($ch); curl_close ($ch); function progress_function($ch,$str) { echo $str; return strlen($str); }
Подобная функция ДОЛЖНА возвращать длину строки, что является обязательным требованием.
Заключение
Сегодня мы познакомились с тем, как можно применить библиотеку cURL в своих корыстных целях. Я надеюсь, что вам понравилась данная статья.
Спасибо! Удачного дня!